
日本や世界の半導体メーカー・会社・企業【分野別で紹介】
製造業

現在、業務プロセスを効率化し、競争優位性を高めるために、あらゆる企業で生成AIを活用するプロジェクトが始まっている。一方、実態として「期待した回答が得られず業務に活用できていない」「回答精度を向上させたいが、改善されない」などの課題が残る。
その要因として、導入フェーズやユースケースに合った改善ができていないことが挙げられる。例えば、「社内データが正しく連携されていないといった精度低下要因に対し、プロンプト改善やファインチューニングを試みてしまう」などである。生成AIが探せない・知らない状態になっているにも関わらず、質問方法を変えただけでは回答精度は上がらない。このように要因と改善策がマッチしないことで回答精度が上がらず、活用を諦めてしまう。そのようなケースを回避するために、本稿では、導入フェーズ別の生成AI回答精度の改善方法について解説したい。
目次
1つ目が「ChatGPT」や「Microsoft Copilot」などを代表とする汎用型の生成AIを個人で使うフェーズである。自身のアイデアの壁打ちや翻訳、要約などに活用するケースであり、すでに多くの人に活用経験があるだろう。
2つ目が、RAG(※)を活用し、社内のデータをAPIで生成AI基盤モデルと連携させることで組織的に生成AIを活用するフェーズである。オープンデータだけでなく、社内規定やマニュアル、営業日報から技術データまで、埋もれがちな社内のナレッジを効率的に有効活用することが可能であり、社内チャットやQ &Aなどの業務効率化が期待できる。
(※)RAG(Retrieval Augmented Generation)とは?仕組みや活用事例についてはこちら
3つ目が自社独自のLLM基盤を構築するフェーズである。自社開発やLLMを開発している企業との提携により、自社特有のLLMを構築することで、社内に蓄積されたデータを検索できるだけでなく、より専門領域や自社特有の技術・ナレッジに特化したAIを独自に拡張することが可能となる。自社のサービス開発など企業の差別化が期待される場合に有効であり、今後このような事例が増えていくことが想定される。
企業の生成AI活用については、この3つの導入フェーズに大きく分類される。そこで本稿では、精度改善のポイントをフェーズ別に解説する。自社がどのフェーズにいるのかを把握し、正しい改善方法を見出すきっかけとしていただきたい。
「ChatGPT」や「Microsoft Copilot」などを代表とする汎用型の生成AIを活用するうえで、精度を向上させるためのポイントをご紹介しよう。
プロンプトとは、生成AIに対して具体的な指示や質問を与えるための入力文を指す。AIがユーザーの意図を理解し、適切な応答を生成するための重要な役割を果たすため、プロンプトの質が高ければ高いほど、回答精度の質が向上される。抽象的な問いであるほど、何を達成したいのか、何に使いたいのか、誰に向けたアウトプットなのかを明確にし、背景情報や条件を盛り込んだ具体的で詳細な指示を記載することがポイントとなる。
<プロンプト入力のコツ>
(例)資料作成において生成AIを活用した解決方法を知りたい場合
POINT1:生成AIに役割を与える
「あなたは製造業の開発者です。」
POINT2:回答させたいものの数や文字数を制限する
「資料作成に生成AIを活用した事例を100字以内で5つ以上教えてください」
POINT3:段階踏んで質問することで、さらに回答を深掘りする
「では、”活用したサービス名” “使いやすさ””カスタマイズ性”で整理してください」
POINT4:出力形式を指定することで複雑な回答を整理
「資料作成における「使いやすさ」と「カスタマイズ性」で評価し、
評価結果を追加して表形式で出力してください」
組織で生成AIを利用するうえでは、社内のデータや文書を活用することが精度向上への第一歩となる。社内情報を生成AIで活用することで、より自社業務にマッチした正確で精度の高い回答を得られるだけでなく、現場社員にとっては、必要なナレッジ・情報に迅速にアクセスすることができ、業務の質を向上させることが可能となる。そこで本章では、社内情報を生成AIに活用するうえでのポイントを紹介する。
RAGとは、LLM(大規模言語モデル)の技術に検索機能を加えた技術、またはそれを使ったサービスを指し、日本語では「検索拡張生成」という。RAGを導入し、社内にあるデータベースや資料・製品マニュアルを連携させることで、自社のナレッジや情報を加味した回答できるようになるため、回答精度を飛躍的に向上させることが可能となる。
RAGを導入しているが、「回答精度が思うように上がらない」といった課題を感じている場合、社内の情報に図や表・グラフなどの非テキストが多く含まれているのではないだろうか。そういった複雑なデータの意味をAIが理解し、回答できなければ、RAGを実装する効果が大幅に限定されてしまう。そのため、社内データに含まれる図や表・グラフなどの複雑なデータを構造化し、「AIが探せる・回答できるデータ」にすることがRAGを実装する上で最も重要であるといっても過言でない。また、データを構造化することで、類似するドキュメントが複数存在する場合でも、「最新のものだけをフィルタリングして回答させる」「編集者で条件をかけて回答させる」ことも可能となる。
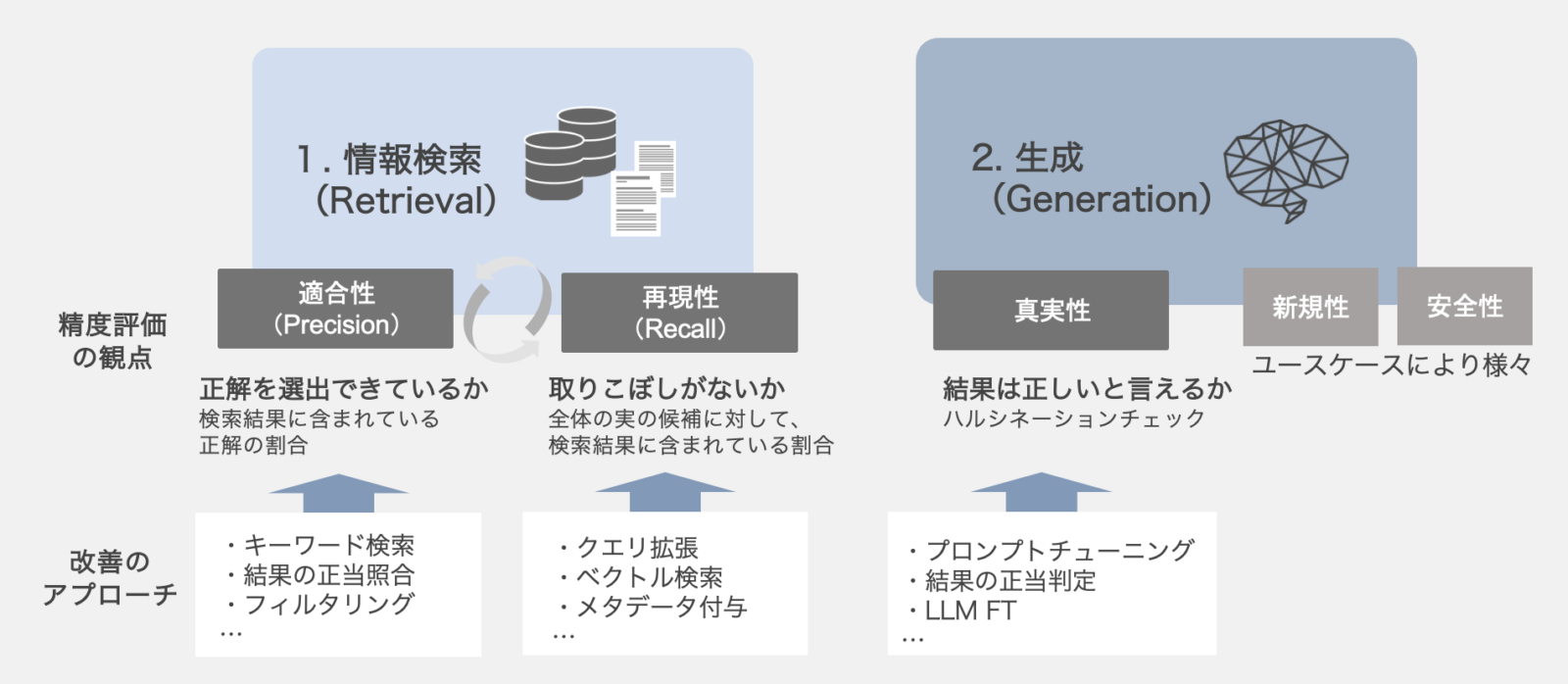
RAGは“検索”と“生成”で構成されているため、課題の特定や検証に関わる変数が多く、精度検証のポイントやアプローチが複雑化している。そのため、「回答精度が上がらないが、どこが要因なのかわからない」といったケースが発生している。RAGを活用する場合、どこに課題があるかによって改善方法も異なるため、それぞれの観点で考えることが重要である。ところが、情報を正しく検索できていないにも関わらず、ファインチューニングで「生成」を改善しようとしてしまうケースも存在する。まずは、どの工程に要因あるのかを正しく評価し、適切な改善アプローチを行うことは必須である。
このフェーズでは、自社特有のLLMを構築することで、より専門領域や自社特有の技術・ナレッジに特化したAIを独自に拡張することが可能となる。
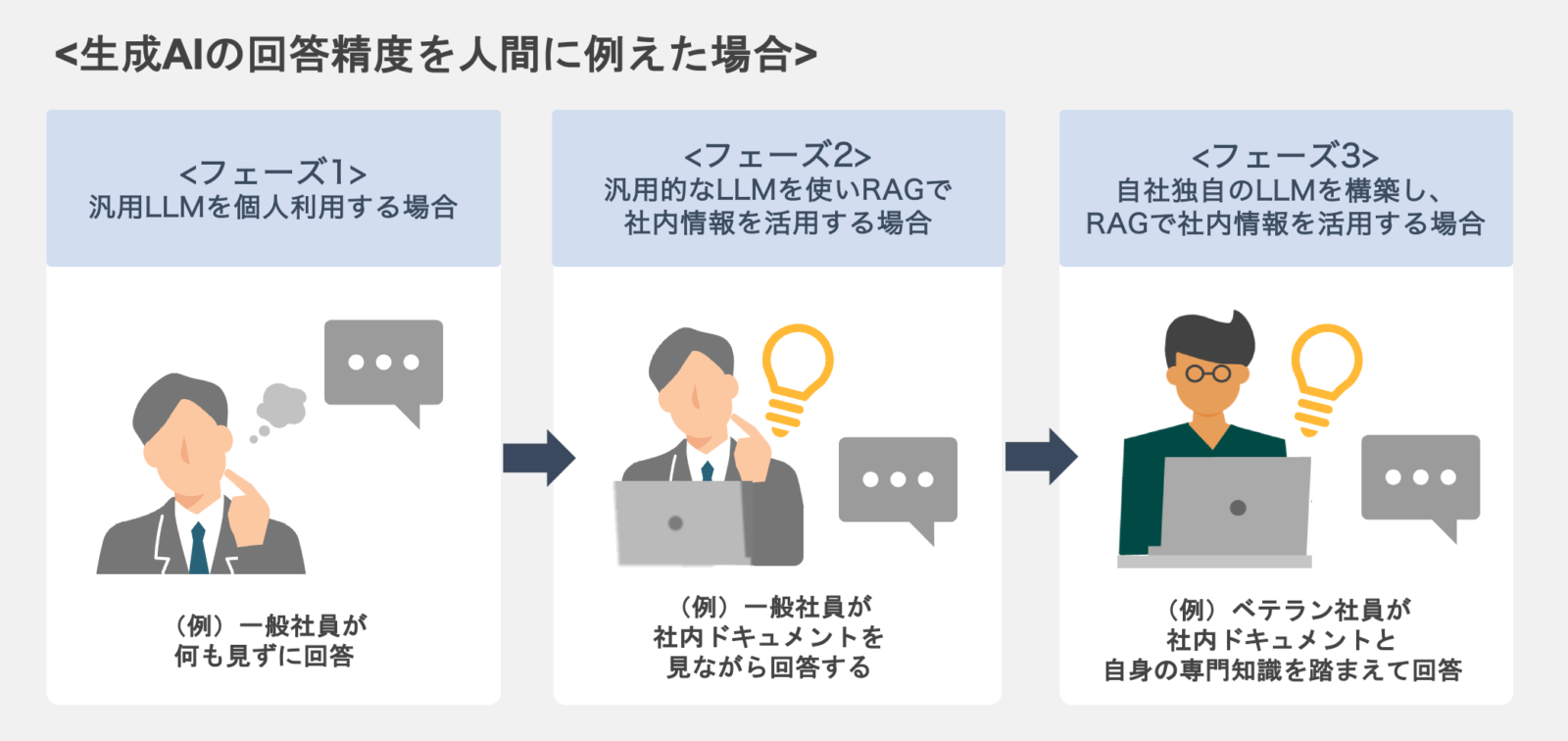
「汎用的なLLMを使い、RAGで社内情報を活用する」フェーズ2と「自社独自のLLMを構築して、RAGで社内情報を活用する」フェーズ3との違いについては、生成AIを人間で例えた場合、「一般社員が社内ドキュメントを見ながら回答する」前者と「ベテラン社員が社内ドキュメントと自身の専門知識を踏まえて回答する」後者である。この二者に回答精度に違いが出るのは明白だろう。
より高い回答精度を期待できるメリットはあるものの、大規模な開発費用やランニングコストがかかる自社LLM構築。また、昨今では、多くのLLMモデルが日進月歩で発表されるなか中で、どのモデルを選択するべきなのか見極めも重要である。そこで、フェーズ3に移行する上で、初期段階で明確にするべきポイントをお伝えする。
<事前に考慮するべきポイント>
・目的と課題:どのような情報をどのような形式で出力させ、何を実現させたいか
・セキュリティ:クラウドとオンプレミスのどちらでデータを管理するか
・利用人数:利用者数はどの程度の規模を想定しているか
・社内調整:学習させたい社内データの提出について関係部署に協力が得られるか
上記を事前に確認しておくことで、投資ポイントやツール選定をスムーズに進められるだろう。
ファインチューニングとは、LLMやAIモデルを特定の用途やデータセットに適応させるために、追加のトレーニングを行うプロセスを指す。自社LLMを独自に開発する場合には、LLMをファインチューニングし、自社知識を踏まえたアイデアや回答結果を出力させることが重要である。例えば、ローマ字の頭文字をとった単語で業界によって意味合いが変わってくるもの(例:「CTR」医療用語としては心胸比。マーケティング用語としてはクリック率を指す)について、LLMを専門的にチューニングすることで、業界に沿った意味合いで回答させることが可能となる。
今後、生成AIを活用した事業構築や情報収集の重要性が増すなか中で、まずは実現したいことを明確にし、ユースケースにあった活用方法を選択することが重要である。一方で、導入フェーズやユースケースに合わせて適切なアプローチをすることができれば、回答精度を飛躍的に向上し、業務のパートナーとして活躍してくれるだろう。
弊社ストックマークでは、RAG精度向上のための「データ構造化〜検証〜実装」にアプローチする構造化プラットフォームStockmark A Technology(SAT)を展開している。「データ構造化」「ナレッジグラフ生成」「RAG評価環境」から「LLMの受託開発」まで支援しており、API経由で自社環境に簡単に接続することも可能である。











