
日本や世界の半導体メーカー・会社・企業【分野別で紹介】
製造業

ChatGPT、Gemini(旧Bard)、Grok、Claudeと、この1〜2年で多くのIT企業が生成AIの開発を行い、まさに群雄割拠の様相を呈している。ただ、生成AIは未だ情報の不確実性が問われているのが現状だ。そのような中注目が集まっているのがRAG(検索拡張生成)という技術だ。本記事では、RAG(検索拡張生成)の仕組みや特徴、LLM(大規模言語モデル)との違いについて解説したい。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
目次
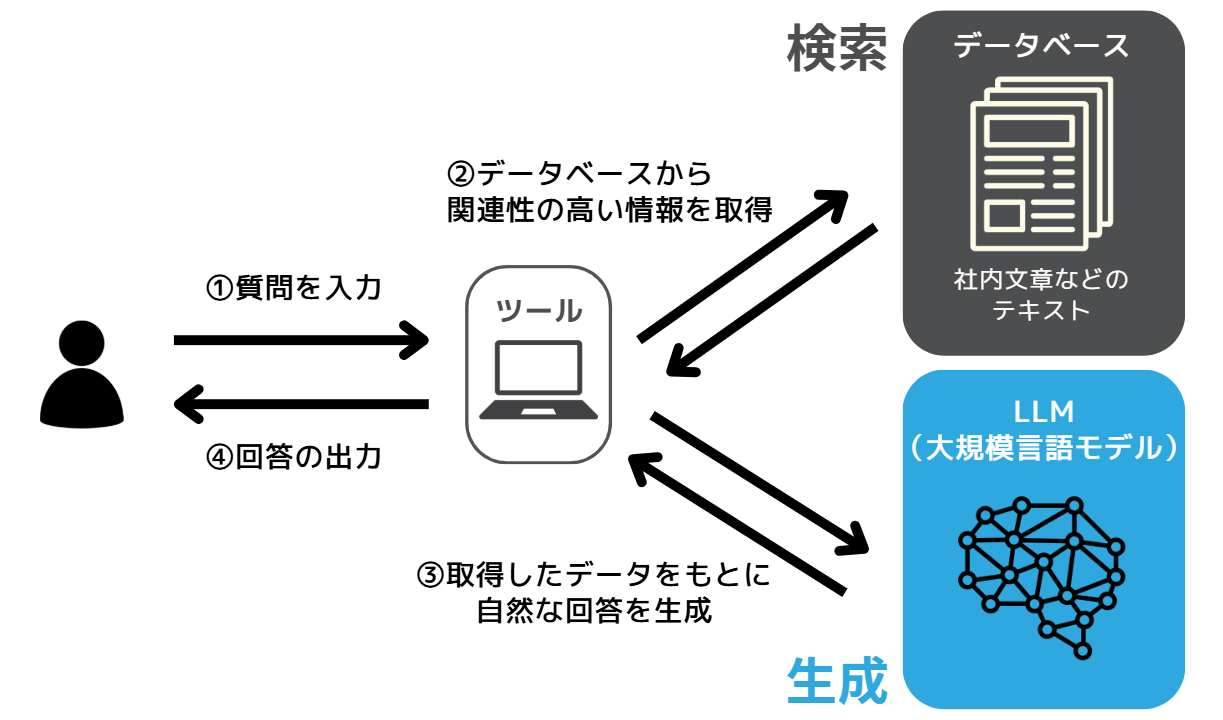
RAGとは、LLM(大規模言語モデル)の技術に検索機能を加えた技術、またはそれを使ったサービスを指す。検索機能を拡張し、信頼性が担保された回答を生成できることから、それぞれの頭文字を取って「RAG」と呼ばれる。読み方はラグ。日本語では「検索拡張生成」という。例えば社内にあるデータベースや資料・製品マニュアルを連携させることで、LLMではカバーできない範囲の情報も含めて回答できるようになることがRAGのメリットだ。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
LLMは自然言語処理に特化した生成AIの1つで、事前に学習・訓練した膨大なデータセットに基づき、テキストを生成することができる。学習済みの知識をもとに応答することは可能だが、リアルタイムに外部の新しい情報を参照することはできない。
それに対して、RAGは外部のデータベースや検索エンジンを活用して、最新の情報を取得するため、より信頼性の高い応答が可能となる。
RAGは外部データベースや検索システムからリアルタイムで情報を検索し、その情報をもとに生成モデルが応答を作成する手法だ。それに対して、ファインチューニングは特定のタスクに特化させる手法を指す。
RAGには、大きく「検索」と「生成」の2つのフェーズが存在する。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
ユーザーから受け取ったクエリ(検索キーワード)をもとに、社内のドキュメントや専用データベース、外部検索エンジンから関連性の高い情報を検索するフェーズだ。検索の方法としては、「キーワード検索」や「ベクトル検索」、前者2つを組み合わせた「ハイブリッド検索」などがある。
キーワード検索は従来の検索エンジンにも搭載されている方法で、クエリ内のキーワードと文書内の単語の一致度をもとに関連性を評価する方法だ。
ベクトル検索は、テキストや画像、音声データをベクトルに変換(複雑なデータを処理しやすい「数値の集まり」の形に変換)し、ベクトル同士の類似度で関連性を分析する。一般的に、RAGでは「キーワード検索」と「ベクトル検索」の弱点を補完するために、「ハイブリッド検索」が用いられることが多い。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
検索フェーズで取得したデータをもとに、LLMを用いてユーザーへ高精度で自然な回答を生成するプロセスだ。さまざまな場所から情報を収集するため、LLMでしばしば起こるハルシネーション(AIが事実とは異なる情報や、実際には存在しない情報を生成する現象)を最小限にとどめることが可能になる。
RAGのプロセスを活用すると、従来の生成AIとは何が異なり、具体的にどのようなメリットを得られるのだろうか。いくつか考えられるメリットを紹介しよう。
インターネット上の大量の情報から回答を生成する場合、時に誤った情報が混ざることがある。一方で、RAGは質問に合った信頼できるデータベースやドキュメントから必要な情報を直接引き出すため、情報の元が明確で正確性も高くなる。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
LLMでは、一般に公開されている既出の情報を根拠としているため、限られた分野・範囲の回答しか生成できない。もし生成できたとしても情報が古かったり、ハルシネーションを起こしたりする恐れが極めて高い。RAGでは、事前に指定されたデータベースやファイルから情報を取得するため、社内文書や作業マニュアルといった非公開情報を扱うことも可能となる。
LLMに最新の情報を基に回答させるには、追加事前学習が必要になってしまう。それに対して、RAGはLLMのように保有するデータを元に回答するのではなく外部データソースを元とするため、情報の更新が容易となり、最新の情報から回答の生成が可能となる。
RAGを活用すれば、単純な情報収集やコンテンツ生成だけでなく、問い合わせ対応や技術文書の作成、データ分析など、より高度で複雑な業務の効率化に役立てることができる。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
従来、社内問い合わせで生成AIを利用するには精度や専門性の観点からファインチューニングが推奨されており、膨大なデータの準備やプロンプトを記述できるスキルや専門的な知識、プログラミングスキルが必要だった。しかし、RAGを使えば適宜データベースに業務マニュアルやFAQ文言集を追加するだけで、専門的な知識やスキルがなくても、リアルタイムでかつ精度の高い問い合わせシステムの作成ができる。
技術に関連する情報は目まぐるしく変化するため、従来の生成AIでは人を介したファクトチェックが必要だった。しかし、RAGではリアルタイムに外部データベースや検索システムから技術的な情報を抽出できるため、ブログ記事やニュース記事などのコンテンツのみならず、専門性が求められる文章の生成も可能となる。
RAGのデータベースに、顧客データや業界トレンド、アンケート調査結果などの情報を登録すれば、市場動向の変化や競合製品の評価などの結果を出力することが可能となる。さらに、人では気づけない傾向やデータ間の関連性をより迅速に効率的に見い出すこともできるだろう。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
ここまでRAGの有用性について解説したが、使用にあたっては注意すべき点がいくつか存在する。
RAGの大きなメリットは保有データに依存せずに、外部のデータベースなどから容易に最新情報の更新ができる点だ。ただし、取り込んだデータベース自体が正しくない場合、不正確な回答が生成されてしまう。取り込んだデータベースに誤りはないか、恣意的な結果ではないかなど入念にチェックすることが大切になる。
「RAG」の実用化でお困りですか?
あらゆる情報を整えて信頼性のある回答を生成できる状態をストックマークが提供します。
サービスを詳しく見てみる
RAGでは、個人情報や機密情報といった秘匿性の高い情報も回答のソースに利用してしまうケースがあるため、取り扱いには注意が必要だ。意図しない情報流出が起こらないよう、一定のアクセス制限や権限管理、データの匿名化・マスキングなどの対策を行うことが肝要といえる。
RAGは、生成AIの能力を飛躍的に向上させる1つの手法といえる。出力する回答は登録データベースに依存するため、機密情報の取り扱いには十分注意をはらわなければいけないが、今後はますます生成AIを活用した事業構築や情報収集の重要性が増してくるだろう。LLMやRAGといった生成AIの最新トレンドを常にウォッチし、自社の事業や研究開発に活かしてみてはいかがだろうか。











